Understanding the Difference Between Unity Catalog and the Hive Metastore
As organizations modernize their data platforms to support lakehouse architectures and enterprise-wide governance, understanding the differences between legacy metadata management and modern solutions becomes critical. This comparison highlights the key distinctions between the traditional Hive Metastore — originally designed for Hadoop-era workloads — and Databricks Unity Catalog, which provides centralized, fine-grained, and scalable governance tailored to today’s cloud-native and multi-workspace environments.
Apache Hive Metastore
The Hive Metastore is the traditional metadata repository for Apache Hive and also used by Spark, Presto, Impala, and Databricks (historically). It stores metadata about databases, tables, partitions, schemas, and locations of data files in HDFS or cloud object stores.
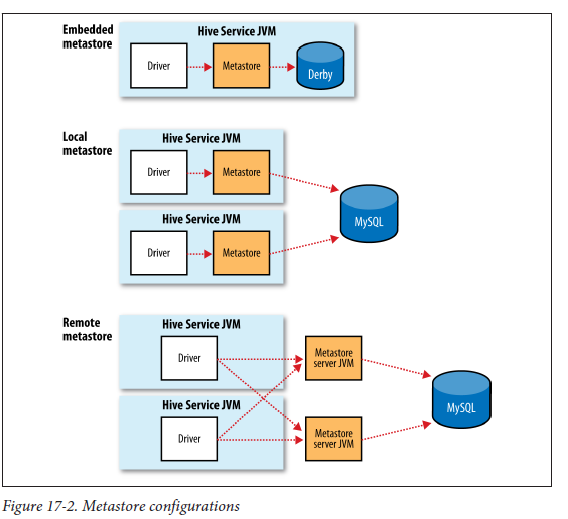
Image source: O'Reilly's "The Hadoop Definitive Guide", Tom White
Key limitations of Apache Hive Metastore:
- Per-workspace / per-cluster scope — each workspace has its own Hive metastore, which makes it hard to share metadata between workspaces.
- Lacks fine-grained access controls (you can only secure at database/table level, and often need external tools like Apache Ranger).
- Metadata is limited in scope (tables, columns, partitions — but not row-level or attribute-level governance).
- Does not track data lineage, audit events, or enforce governance standards.
In short, the Hive Metastore was never designed for today’s scale or governance needs. Its centralized, mutable metadata and directory-based partition tracking make it brittle, slow, and operationally fragile at enterprise scale. These architectural limits set the stage for the next evolution in data lake design—one that treats tables as first-class, self-describing objects rather than folders of files.
Enter Apache Iceberg.
Apache Iceberg
Apache Iceberg is an open table format that fundamentally re-architects how data lake tables are defined, moving beyond the brittle, slow, and limited model of traditional Hive tables and their reliance on the Hive Metastore (HMS).
Apache Iceberg is a modern open table format that solves the major limitations of traditional Hive tables.
The previous Hive model relied on the Hive Metastore (HMS) to track every table partition in an external database. This approach was slow at scale and non-atomic. This risked data corruption, data loss, and inconsistent reads.
Iceberg solves this by creating self-contained tables. Each table stores its own complete, versioned metadata (schema, partitions, and data file locations) in files directly alongside the data. This design provides high performance by avoiding slow directory listings, guarantees data consistency with atomic transactions, and enables powerful features like time travel (querying the table as it was at a specific time) and schema evolution.
While compatible, Iceberg limits the role of HMS to an optional pointer for table discovery, offering a seamless migration path from legacy systems.
The limitations of the Hive Metastore—such as its lack of centralized governance, fine-grained access controls, data lineage, and comprehensive auditing— informed the introduction of Unity Catalog, which provides these features for a modern data lakehouse. The features introduced with Unity Catalog set up customers to move forward by providing a unified, secure, and scalable governance layer that manages all their data assets, like tables, files, and ML models, consistently across multiple workspaces.
From Iceberg to Delta Tables
While Apache Iceberg reimagined how tables are structured on the data lake, Databricks took these same principles further with Delta Lake — its default open table format.
Delta Lake builds on similar ideas of versioned, self-describing tables but integrates deeply into the Databricks runtime, providing ACID transactions, schema enforcement, time travel, and scalable metadata management optimized for large-scale analytics and machine learning. Like Iceberg, Delta Lake eliminates the fragility of directory-based tables from the Hive Metastore, but it also adds performance optimizations and native compatibility with Databricks’ Lakehouse engine.
With open formats like Delta Lake (and now Apache Iceberg supported natively as well), the focus shifts from how data is stored to how it’s governed. This is where Databricks Unity Catalog enters the picture — delivering a unified governance layer that secures, catalogs, and manages all your open-format data, whether in Delta, Iceberg, or Parquet, across every workspace and cloud environment.
Databricks Unity Catalog
Unity Catalog is Databricks’ next-generation data governance and cataloging solution, built for the lakehouse architecture. It’s a centralized, cross-workspace catalog that provides unified governance over all your data assets.
Key capabilities:
- Centralized governance: Single catalog for all Databricks workspaces in an account — no need to duplicate or synchronize metadata.
- Fine-grained access control: Supports secure access down to columns, rows, and attributes with SQL-standard GRANT statements.
- Data lineage: Automatically captures lineage of tables/views, so you can trace where data came from and how it’s transformed.
- Audit & compliance: Logs all access and changes for governance and regulatory compliance.
- Object types: Governs more than just tables — includes files, functions, models, etc.
- Integrated with cloud-native identity & access management: (e.g., Azure, AWS IAM).
Databricks Unity Catalog is a unified governance layer that manages data access, security, and metadata for all your data assets — including tables stored in open formats like Apache Iceberg.
Summary Comparison Table
| Feature | Hive Metastore | Unity Catalog |
|---|---|---|
| Scope | Per workspace | Cross-workspace (centralized) |
| Granularity of permissions | Database/Table | Database/Table/Column/Row |
| Lineage tracking | ❌ No | ✅ Yes |
| Audit logs & compliance | Limited | Comprehensive |
| Governed assets | Tables & partitions | Tables, files, ML models, etc. |
| Cloud-native integration | ❌ No | ✅ Yes |
| Sharing across workspaces | Difficult | Seamless |
Summary
Hive Metastore was built for legacy Hadoop-style big data workloads and offers only basic, siloed metadata management.
Unity Catalog, in contrast, with Delta Tables is built for the modern lakehouse — delivering centralized, secure, and fine-grained governance at scale. In the next article we will dig further into how Delta Tables can be used in the retail industry for product management.
Next in Series
Building a Retail Product Delta Table with Databricks Unity Catalog
In this article we get you going quickly building Delta Tables with CTAS statements and Unity Catalog on Databricks.
Read next article in series