
An Introduction to NVIDIA's Multi-Instance GPUs Under Kubernetes
Author: Josh Patterson
Date: 4/20/2021
In this post we provide an overview of NVIDIA's Multi-Instance (MIG) GPU technology as managed by Kubernetes. To do this we cover the following topics:
- Key terms and definitions
- Core Concepts of MIG
- How to Configure MIG under Kubernetes
MIG is a technology introduced with the new NVIDIA DGX-A100 and can partition the A100 GPU into as many as seven instances, each fully isolated with their own high-bandwidth memory, cache, and compute cores.
This post is an entry in a series on the economics of machine learning hardware. A previous post dealt with Forecasting Your AWS GPU Cloud Spend for Deep Learning.
GPU hardware is getting bigger and faster, but the need to dedicate a single GPU to a single user or task is hitting the headwinds of heterogenous workloads in the enterprise. Allowing a CPU to be shared amongst multiple processes is not a new concept and as GPUs become more general purpose they are gaining similar capabilities. Recently NVIDIA introduced MIG technology in the A100 line of GPUs to allow A100 GPUs to be partitioned into smaller virtual GPUs called "MIG devices" to share a single GPU across multiple processes.
In the realm of shared infrastructure efficiency is key and Kubernetes helps maximize resource usage. Allowing a full A100 GPU to be shared across multiple workloads with MIG and then all of these partitioned MIG resources to be managed by Kubernetes helps maximize efficiency and utilization in a data center.
There are 3 Form Factors of GPU Infrastructure:
- Single GPU Workstations (for single users)
- Single GPU Servers (for development teams or small teams)
- Clusters of GPU Servers (larger organizations)
The NVIDIA DGX-A100 is the latest in NVIDIA's DGX line of cluster GPU packages for the data center and has :
- 8 x NVIDIA A100 GPUs, each with 40GB (or 80GB, depending on model) of GPU RAM (320GB / 640GB GPU RAM, total)
- 6 NVIDIA NVSwitches
- dual AMD Rome 7742 CPUs (128 cores total)
- either 2TB or 1TB system RAM
This amount of GPU compute density coupled with the rising demand to colocate
- different classes of machine learning training workloads
- data prep and data engineering workflows
- inference serving
An Overview of NVIDIA's Multi-Instance GPUs (MIG)
With MIG a single NVIDIA A100 GPU can be partitioned into up to 7 independent MIG devices. Each MIG device runs concurrently and has its own memory, cache, and streaming multiprocessors. With 8 physical GPUs in the DGX-A100 system, you could potentially have up to 56 separate MIG Devices at the same time.
In the diagram below we see how a MIG-capable GPU can be divided up into multiple MIG devices

Each block in the diagram above represents a potential MIG device that we could configure for use on a single GPU. A MIG device consists of the
3-tuple of
- a top level GPU
- a
GPU Instancecreated inside that GPU - a
Compute Instancecreated inside that GPU Instance
A GPU instance is the first level of partitioning on a MIG capable GPU. It creates a wrapper around a fixed set of memory slices, a fixed set of compute slices, and a fixed set of "other" GPU engines (such as jpeg encoders, dma engines, etc.)
A Compute Instance is the second level of partitioning on a MIG capable GPU. It takes some subset of the compute slices inside a GPU Instance and bundles them together. Each Compute Instance has dedicated access to the compute slices it has bundled together, but shared access to its wrapping GPU Instance's memory and "other" GPU Engines.
While it is possible to subdivide a GPU Instance further with Compute Instances, when dealing with managing MIG devices under Kubernetes we always assume that a MIG device consists of a single GPU Instance and a single Compute Instance.
This gives us a MIG device naming convention that refers to a MIG device by:
[GPU Instance slice count]g.[total memory]gb
Example: 3g.20gb
(Note: In this naming convention, the GPU Instance count and Compute Instance count will always be the same.)
For more details on limitations on GPUs in MIG mode check out NVIDIA's Challenges Supporting MIG in Kubernetes.
Notes on Enabling MIG Under Kubernetes
There are components to install on the DGX to support MIG. Further, all GPUs must be configured into MIG mode and partitioned into MIG devices before we can select a MIG device resource under Kubernetes.
Assuming we're using the mixed strategy for managing GPUs with MIG and Kubernetes, we would configure each GPU with a specific MIG profile. This profile is a set of partitions for that specific GPU that give us a set of MIG Device types that will be available in Kubernetes.
You can see an example of this below where we are creating 3 different MIG devices of different sizess on the GPU:
When configuring GPUs for MIG partition profiles with the nvidia-smi tool, you'll need to verify the gpu instance profile ids with the following command:
(Note: The MIG GPU instance profile ids are somewhat arbitrary and not fixed. For addition help in defining MIG Partitions, check out The MIG Partiton Editor (nvidia-mig-parted). It is a tool designed for system administrators to make working with MIG partitions easier.)
There are multiple ways to combine sets of MIG device types to build MIG partitions. There are constraints and limitations on what you can and cannot do in terms of combining certain MIG device types on a single A100. For more background on this topic, check out NVIDIA's Supporting MIG in Kubernetes document.
Notes on Using MIG Devices Under Kubernetes
When we request a specific MIG device type, we use the
MIG device naming convention we introduced above (e.g., "3g.20gb"). Our limitations is that per node (e.g., "machine" or "host") all of the GPUs must be of the same product line. However, some GPUs may be MIG-enabled while other GPUs may not be.
Previously in Kubernetes we'd select a GPU resource type with:
nvidia.com/gpu
Now we select a MIG device in Kubernetes with the following resource type schema:
nvidia.com/mig-<slice_count>g.<memory_size>gb
Let's take a look at how we'd use this in a job definition. The mixed strategy for a (4 memory, 3 compute) device on an A100:
apiVersion: v1
kind: Pod
metadata:
name: gpu-example
spec:
containers:
- name: gpu-example
image: nvidia/cuda:11.0-base
resources:
limits:
nvidia.com/mig-3g.20gb: 1
nodeSelector:
nvidia.com/gpu.product: A100-SXM4-40GB
As you can see above, once you have MIG working under Kubernetes you can select MIG devices in a similar method to how you'd normally select a physical GPU.
Matching MIG Devices and Target Workloads
To give you a better sense as to what workloads will work best for different types of MIG devices we put together the table below.
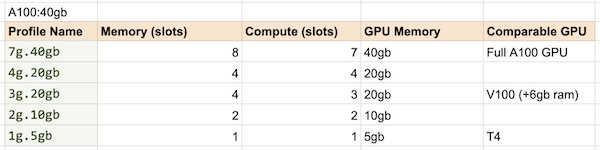

This table was compiled/estimated based on discussions with NVIDIA engineers and other published A100 benchmarks. Some quick further notes:
- The A100 GPU is roughly 2.5x more powerful than the V100 GPU
- A single V100 is available on AWS as a p3.2xl instance
Although MIG has certain limitations (such as No GPU to GPU P2P (either PCIe or NVLink) is supported), MIG does work with the CUDA programming model with no changes. MIG also works with existing Linux OSs, Containers, and Kubernetes (with plugin install).
A quick rule of thumb for how to match up workloads (see also: Resource Requirements for Different Types of Deep Learning Workflows) with MIG device types is:
| MIG Device Type | Workload Match |
|---|---|
7g.40gb |
heavier deep learning training jobs |
3g.20gb |
medium machine learning training jobs (Kaggle-type notebooks) |
1g.10gb |
Inference (batch-1) workloads (low-latency models), development Jupyter notebooks |
4g.20gb, 2g.10gb) between the 3 listed above allow for further flexibility for workloads that "don't exactly fit in one of the buckets".
Summary
In this article we gave the reader a light overview of how MIG is enabled and used under Kubernetes.
In a future article we will look at how to build an on-premise value-model across MIG devices.
Did you like the article? Do you think we are making a poor estimation somewhere in our calculations? Reach out and tell us.
MLOps Questions?
Are you looking for a comparison of different MLOps platforms? Or maybe you just want to discuss the pros and cons of operating a ML platform on the cloud vs on-premise? Sign up for our free MLOps Briefing -- its completely free and you can bring your own questions or set the agenda.