Bordereaux Data Integration into Databricks Delta Tables with Tabsdata
Insurance teams depend on timely, accurate claim data to make fast decisions. However, when Third-Party Administrators send claim data as spreadsheets by email—often with mismatched schemas—it creates bottlenecks that slow things down. Engineers end up cleaning and restructuring files instead of building reliable workflows, and business leaders wait longer for insights they need today.
In this post, we’ll show how Tabsdata and Databricks can empower a single engineer to automate an entire insurance claim workflow end-to-end: from collecting claim files straight out of Gmail, to standardizing and enriching them, to publishing clean, versioned data into Databricks for analysis.

The result is a workflow that saves time, reduces errors, and gives your claims team the data they need when they need it.
What is Tabsdata
Tabsdata follows a Pub/Sub approach that makes data integration more scalable and flexible than traditional data integration pipelines. Instead of extracting and loading data directly into your data platform, you publish datasets into tables within the Tabsdata Server. From there, Databricks (or any other platform) can subscribe to those tables.
Between publishing and subscribing, you can add transformation steps to clean, enrich, or reshape the data as needed. Each step in this workflow is implemented as a Tabsdata Function, which is a simple Python function that either reads from or loads data into Tabsdata Tables.
Functions can be triggered manually or automatically when new data needs to be processed. Every run of a function creates a new version of its table, and all versions of all tables are stored in the server. That means you can sample past versions of your tables at any point in time, making time travel, auditing, and debugging straightforward and easy.
Why Tabsdata
Tabsdata provides seamless ingestion and transformation capabilities while giving you significant advantages in lineage, governance, and orchestration.
Every Tabsdata Table is automatically versioned and stores the full history of both its data and schema. When a new version of a table is created, Tabsdata infers the schema directly from the data being written, removing the need to define or enforce a schema in advance. This approach preserves the metadata and semantics of your source data, gives you clear visibility into how that data evolves over time, and enables you to address schema drift proactively instead of managing it defensively. Together these features create a complete, meaningful timeline that shows how your data changes over time, when those changes occur, and what those changes mean.
These versioned tables form the backbone for how work is orchestrated in Tabsdata. Since Tabsdata Functions only interact with Tables, either by reading from them or writing to them, this allows Tabsdata to infer execution order and automatically orchestrate your workflow. When a table gets new data, any functions that depend on that table run automatically. This declarative orchestration removes the need to manually create and maintain fragile DAGs and gives you greater confidence in the reliability of your data.
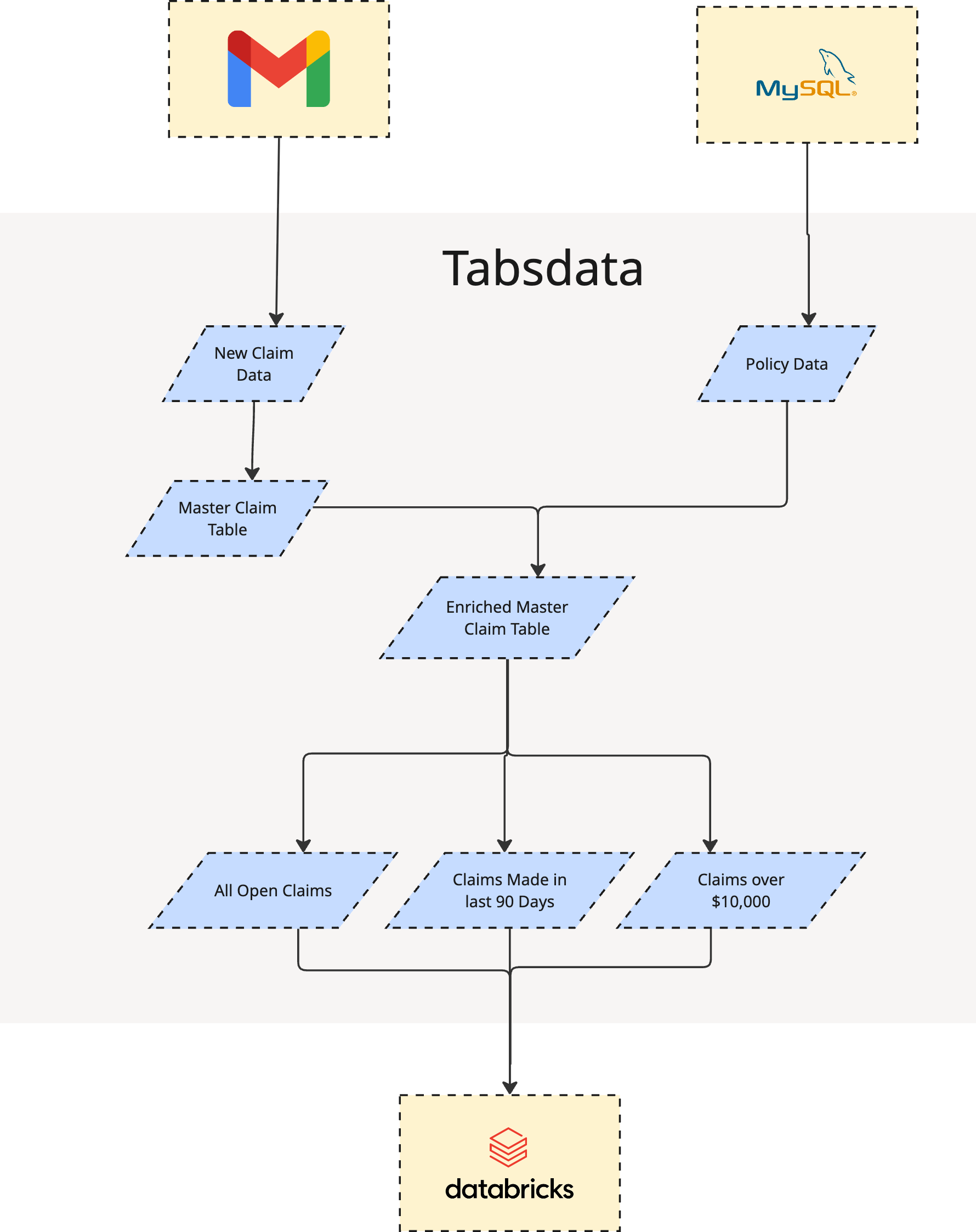
The Plan: From Gmail & MySQL to a Governed Lakehouse
To automate TPA claims processing, we’ll implement a simple, reproducible pipeline:
- Publish raw claims data from Gmail into Tabsdata.
- Publish policy data from MySQL into Tabsdata.
- Transform and enrich the claim data with policy data.
- Subscribe the processed (clean, versioned) data into
Databricksfor analytics.
Target Schemas
The policy data we ingest will use the following schema:
| Field Name | Type | Description |
|---|---|---|
| policy_number | String | Unique identifier for the policy |
| months_insured | Integer | Total number of months the policy has been active |
| has_claims | Boolean | Indicates whether the policyholder has filed claims |
| insured_name | String | Name of the policyholder |
| policy_start_date | String | Date when the policy began |
| reserve_amount | Float | Funds reserved for potential claims |
| total_incurred | Float | Total claim costs incurred to date |
| claim_propensity | Float | Model-predicted likelihood of a claim |
| broker_id | String | Identifier for the broker who issued the policy |
Our claim data files may arrive with non-uniform schemas. We standardize all claim data to this canonical schema:
| Field Name | Type | Description |
|---|---|---|
| policy_number | String | Unique identifier for the policy |
| months_insured | Integer | Number of months the policy has been active |
| has_claims | Boolean | Whether the policyholder has filed any claims |
| items_insured | Integer | Number of items covered under the policy |
| claim_reference | String | Unique reference for the claim |
| insured_name | String | Name of the policyholder |
| policy_start_date | String | Date the policy began (YYYY-MM-DD) |
| date_of_loss | String | Date when the loss event occurred |
| date_reported | String | Date the claim was reported |
| claim_status | String | Current status (e.g., open, closed, pending) |
| loss_type | String | Type of loss (e.g., theft, accident, fire) |
| paid_amount | Float | Amount already paid on the claim |
| reserve_amount | Float | Funds reserved for potential future payments |
| total_incurred | Float | Total claim costs (paid + reserved) |
| claim_propensity | Float | Model-predicted likelihood of a claim |
| broker_id | String | Identifier of the issuing broker |
| date_loaded | Date | Date the record was ingested into the system |
Getting Started
Install Tabsdata locally and start the server, then authenticate and create a collection to organize your workflow assets.
pip install tabsdata
# start the local server
tdserver start
# login to Tabsdata
td login --server localhost --user admin --role sys_admin --password tabsdata
# create a collection for this workflow
td collection create --name claim_processing
Inside this collection, we’ll build six functions: two publishers, three transformers, and one subscriber.
Publisher #1: Policy_dim_pub (MySQL → Tabsdata)
To enrich claims data, we need the latest policy records. This publisher uses the Tabsdata MySQL connector to pull policy data and load it into the policy_dim table.
@td.publisher(
source=td.MySQLSource(
uri=os.getenv("MYSQL_URI"),
query=["SELECT * FROM `policy_dim`"],
credentials=td.UserPasswordCredentials(MYSQL_USERNAME, MYSQL_PASSWORD),
),
tables=["policy_dim"],
trigger_by=["claims_fact_today"],
)
def policy_dim_pub(tf: td.TableFrame):
return tf
Publisher #2: Claims_fact_pub (Gmail → Tabsdata)
This function connects to Gmail and extracts all unread CSV attachments. It standardizes each file’s schema, unions the results, de-duplicates, and writes to claims_fact_today.
def standardize_schema(tf: td.TableFrame):
target_schema = {
"policy_number": td.String,
"months_insured": td.Int64,
"has_claims": td.Boolean,
"items_insured": td.Int64,
"claim_reference": td.String,
"insured_name": td.String,
"policy_start_date": td.String,
"date_of_loss": td.String,
"date_reported": td.String,
"claim_status": td.String,
"loss_type": td.String,
"paid_amount": td.Float64,
"reserve_amount": td.Float64,
"total_incurred": td.Float64,
"claim_propensity": td.Float64,
"broker_id": td.String,
}
tf = tf.with_columns(
*[
(
td.col(name)
if name in tf.columns()
else td.lit(None).cast(dtype).alias(name)
)
for name, dtype in target_schema.items()
]
)
tf = tf.select(list(target_schema.keys()))
return tf
@td.publisher(
source=GmailPublisher(), # Initialize the source plugin
tables="claims_fact_today", # Define the output table name
)
def claim_fact_pub(tf: List[td.TableFrame]):
tf = [standardize_schema(tf1) for tf1 in tf]
union_tf = functools.reduce(lambda a, b: td.concat([a, b]), tf)
union_tf = union_tf.with_columns(td.lit(date.today()).alias("date_loaded"))
return union_tf.unique(subset=["policy_number", "claim_reference"], keep="first")
Transformer: append_claims_today_to_master_trf
The claims_fact_today table only holds the latest batch of claim data. This transformer takes the claims_fact_today and claims_fact_master tables as input, appends claims_fact_today to claims_fact_master and returns claims_fact_master.
@td.transformer(
input_tables=["claims_fact_today","claims_fact_master"],
output_tables=[
"claims_fact_master"
],
)
def append_claims_today_to_master_trf(claims_fact_today, claims_fact_master):
if claims_fact_master is None:
claims_fact_master = claims_fact_today.clear()
claims_fact_master = td.concat([claims_fact_today,claims_fact_master])
return claims_fact_master
Transformer: master_fact_trf
This transformer takes claims_fact_master and policy_dim as input, joins policy_dim to claims_fact_master, coalesces overlapping fields, and outputs the data into the table claims_fact_master_enriched.
@td.transformer(
input_tables=["policy_dim", "claims_fact_master"],
output_tables=["claims_fact_master_enriched"],
)
def master_fact_trf(policy_dim: td.TableFrame, claims_fact: td.TableFrame):
key = "policy_number"
master = claims_fact.join(policy_dim, on=key, how="left")
overlapping = list(set(policy_dim.columns()) & set(claims_fact.columns()) - {key})
master = master.with_columns(
[pl.coalesce(col + "_right", col).alias(col) for col in overlapping]
)
master = master.select(
[
col
for col in master.columns()
if col not in [i + "_right" for i in overlapping]
]
)
master = master.filter(td.col("claim_reference").is_not_null())
return master
Transformer: master_categorize_trf
Business units often need tailored claim subsets. This takes claims_fact_master_enriched as input and creates three tables as output:
- open_pending_claims – currently open claims
- claims_last_90_days – claims reported within the past 90 days
- paid_amount_greater_10000 – claims with payouts over $10,000
@td.transformer(
input_tables=["claims_fact_master_enriched"],
output_tables=[
"open_pending_claims",
"claims_last_90_days",
"paid_amount_greater_10000",
],
)
def master_categorize_trf(claims_fact_master: td.TableFrame):
open_pending_claims = claims_fact_master.filter(td.col("claim_status") == "Open")
claims_last_90_days = claims_fact_master.with_columns(
(td.lit(dt.date.today()).cast(td.Date) - td.col("date_reported").cast(td.Date))
.dt.total_days()
.alias("days_since_reported")
)
claims_last_90_days = claims_last_90_days.filter(
td.col("days_since_reported") <= 90
)
paid_amount_greater_10000 = claims_fact_master.filter(td.col("paid_amount") > 10000)
return open_pending_claims, claims_last_90_days, paid_amount_greater_10000
Subscriber: Databricks (Tabsdata → Lakehouse Delta Table)
Finally, we push our processed and curated tables into Databricks Delta Tables with Unity Catalog for analysts and business users. We’ll publish multiple outputs into governed Delta tables.
@td.subscriber(
tables=[
"claims_fact_master_enriched",
"open_pending_claims",
"claims_last_90_days",
"paid_amount_greater_10000",
],
destination=td.DatabricksDestination(
host_url=os.getenv("databricks_host_url"),
token=td.EnvironmentSecret("databricks_token"),
tables=[
"claims_fact_master_enriched",
"open_pending_claims",
"claims_last_90_days",
"paid_amount_greater_10000",
],
volume=os.getenv("volume"),
catalog=os.getenv("catalog"),
schema=os.getenv("schema"),
warehouse=os.getenv("warehouse"),
if_table_exists="replace",
schema_strategy="update",
),
)
def databricks_sub(
claims_fact_master_enriched: td.TableFrame,
open_pending_claims: td.TableFrame,
claims_last_90_days: td.TableFrame,
paid_amount_greater_10000: td.TableFrame,
):
return (
claims_fact_master_enriched,
open_pending_claims,
claims_last_90_days,
paid_amount_greater_10000,
)
The Result: A Ready-to-Use, Versioned Claims Lakehouse
With a few lines of code, we were able to create an ingestion and transformation workflow for Insurance teams to use.
Registering these functions was the only thing we had to do in order to make this workflow operational.
- No hidden jobs
- No manual wiring of tasks into a DAG
- No manual table creation or need to pre-define a schema for our tables
Due to Tabsdata's declarative architecture, many of the complex aspects of building data pipelines are handled automatically under the hood. Tables are automatically created on function registration, table schema is inferred from the data committed into the table at function invocation, schema is scoped to table versions, and every table version created is automatically cached and available to sample at any time. This means that even if our source data experiences schema drift, not only will Tabsdata adapt to that schema, it will also track that schema drift in the table's lineage history, giving us the deeper context into when and how our data is changing.
Before any of this data is even in Databricks, Insurance teams can use the Tabsdata UI to view any of the Tabsdata Tables generated by the execution of our workflow. Within the UI, they can also run SQL queries on the data, view the schema, and access historical versions of the data from previous invocations of our workflow.
Next in Series
Understanding the Difference Between Unity Catalog and the Hive Metastore
In this article we give a breakdown of the key differences between the legacy hive metastore and the modern Databricks Unity Catalog.
Read next article in series