Retail Supplier Logistics Contract Delivery SLA Information Extraction with Agent Bricks
Much of the world’s most valuable information remains locked inside spreadsheets, PDFs, and text documents—especially contracts that lack a consistent structure or schema. For decades, this made it difficult to automatically extract key facts or metrics, as every document had its own quirks and formatting. Enter large language models (LLMs). With their ability to understand context and nuance, LLMs make it possible to transform unstructured text into structured, machine-readable data. This shift marks one of the most powerful new frontiers in workflow automation—where organizations can finally convert raw text into operational insights. In this article, we’ll explore how Databricks Agent Bricks enables companies like Big Cloud Dealz to build governed information-extraction agents that turn retail logistics contracts into structured JSON data, ready for analysis in the lakehouse.
What is Information Extraction?
Information extraction is the process of using large language models (LLMs) to automatically identify and structure key facts, entities, and relationships from unstructured text—transforming free-form documents into machine-readable data such as tables, JSON, or database records. Information extraction using LLMs falls under into the emerging set of use cases in Generative AI as a sub-type of "workflow automation".
Generative AI is redefining workflow automation by adding cognitive decision-making and adaptability to traditional robotic process automation (RPA). While RPA handles structured, repetitive tasks, generative AI expands the scope to include unstructured data and complex judgments. This fusion allows organizations to automate not just routine operations, but also tasks requiring contextual understanding—such as processing customer requests, analyzing claims data, or interpreting technical diagnostics—making automation more flexible, accurate, and scalable.
This article will take you through how to extract structured JSON data from a retail supplier logistics text contract in markdown format.
In our previous Agent Bricks article, we designed and deployed a knowledge assistant (RAG) agent that queried a set of documents with embeddings and then used that information to answer questions with LLMs. used a Genie space as our knowledge source. In this project we're building an agent that processes text contracts into structured information with LLMs that can be operationalized in the data lakehouse.
Information Extraction with Agent Bricks
Databricks Agent Bricks simplifies enterprise AI deployment by collapsing months of complex system engineering into a governed, lakehouse-native platform. It lets organizations quickly build and manage intelligent assistants directly on their structured and unstructured data, with full governance through Unity Catalog. Running securely within the Databricks Lakehouse, Agent Bricks ensures accurate, compliant, and scalable access to enterprise knowledge—giving business users instant, reliable insights while freeing engineering teams to focus on data quality and workflow integration.
We start out by clicking on the Agent Bricks button on the left side toolbar as shown in the image below.
From there we'll be presented with a list of Agent Bricks templates for different types of projects. For this project we are going to select the Information Extraction project type, as shown in the image below.
How to Think About Information Extraction in Practice
We're using the Information Extraction project type here because we want to describe the fields we want to extract from the raw text document and provide a specific place in our output json data structure where the data should go.
Let's start with the end in mind, and build up the json data structure we want from any given retail logistics SLA contract. Below you can see a json document that has the 6 types of information we need from each contract along with the two sub-fields for each type.
{
"service_expectations": {
"on_time_delivery": {
"target_percent": 95,
"tolerance_days": 1
},
"in_full_delivery": {
"target_percent": 95,
"tolerance_days": 1
},
"otif": {
"target_percent": 95,
"tolerance_notes": "rolling 3 month average"
},
"average_lead_time": {
"target_calendar_days": 7,
"tolerance_days": 1
},
"asn_accuracy": {
"target_percent": 99,
"tolerance": "n/a"
},
"damage_rate": {
"target_percent": 0.4,
"tolerance_note": "per shipment"
}
}
}
The trick is, for any of us who have ever had to do manual information extraction from documents, that few vendors will have the exact same word, excel, or text document format or structure, so it makes it a game of "hunt and peck" to find what you need. This is incredibly tedious in practice for a person to do manually and has historically been difficult for NLP-methods or if-then statements to try and automate extraction.
Enter LLMs.
The crazy thing about LLMs is that they can do the "hunt and peck"-thing fairly well, especially with some prompt magic, and are much better than people at being consistently good at extracting information from raw text documents. Below you can see an example retail logistics shipping contract that defines SLA terms.
---
## **Shipping Service Level Agreement (SLA)**
**Between:**
**Big Cloud Dealz, Inc.** (“Retailer”)
and
**Georgia-Pacific LLC** (“Supplier”)
**Effective Date:** May 1, 2026
**Agreement Term:** 12 months with annual review
---
### **1. Policy Statement**
Big Cloud Dealz and Georgia-Pacific mutually commit to maintaining a consistent, efficient, and transparent supply relationship that ensures uninterrupted flow of packaging, paper, and cleaning products to Retailer’s distribution centers and retail stores.
This agreement establishes measurable service standards that define the expectations for **delivery accuracy, timeliness, data integrity, and logistics quality**.
---
### **2. Objectives**
* Guarantee that all products are delivered **on time, in full, and damage-free**.
* Ensure **data synchronization** between Retailer and Supplier systems through accurate EDI transactions.
* Minimize downstream supply chain costs through improved visibility and proactive communication.
* Create a **continuous improvement framework** with transparent KPI tracking.
---
### **3. Scope of Agreement**
This SLA covers all goods shipped from Georgia-Pacific manufacturing facilities and distribution centers to Big Cloud Dealz facilities within the United States and Canada.
Applies to:
* Corrugated packaging, paper goods, janitorial supplies, and tissue products.
* Both **regular replenishment** and **promotional shipments**.
* Shipments under LTL, FTL, and small parcel modes.
* Transactions conducted under Big Cloud Dealz’ approved EDI standards (850, 855, 856, 810).
---
### **4. Service Expectations**
#### **4.1 Delivery and Fulfillment Standards**
| KPI | Target | Tolerance | Description |
| -------------------------- | --------------- | ----------------------- | ----------------------------------------------------- |
| **On-Time Delivery (OTD)** | ≥ 96% | ±1 day | Orders delivered within the confirmed delivery window |
| **In-Full Delivery (IFD)** | ≥ 99% | N/A | Ordered quantity vs. received quantity |
| **OTIF (On-Time In-Full)** | ≥ 95% | Rolling 3-month average | Combined OTD and IFD rate |
| **Average Lead Time** | 7 calendar days | ±1 day | PO acknowledgment to delivery date |
| **ASN Accuracy** | ≥ 99% | N/A | EDI data matches receiving data |
| **Damage Rate** | ≤ 0.4% | Per shipment | Damaged goods ÷ total goods received |
---
### **5. Operational Obligations**
#### **5.1 Supplier Responsibilities**
* Transmit **ASN (EDI 856)** at least **4 hours before carrier departure**.
* Provide valid **PO, SKU, lot, and case-level details** on all shipping documentation.
* Use **Retailer-approved carriers** or submit alternative carrier requests 48 hours before shipment.
* Package all goods to Retailer **Packaging Standard P-7.3**, including pallet height ≤ 72”, corner protection, and stretch-wrap containment.
* Manage and fund expedited freight in cases where Supplier-caused delay impacts Retailer inventory.
#### **5.2 Retailer Responsibilities**
* Provide accurate and timely purchase order data.
* Acknowledge ASN receipt within 2 hours of system transmission.
* Provide performance feedback monthly and participate in quarterly performance reviews.
---
### **6. Performance Measurement and Reporting**
* Georgia-Pacific shall provide **monthly KPI summaries** for OTIF, ASN accuracy, and damage rate.
* Big Cloud Dealz will review supplier performance using **Databricks Vendor Metrics Dashboard**, integrating SLA data from Unity Catalog.
* **Quarterly Performance Review Meetings** will evaluate:
* KPI compliance
* Corrective action follow-ups
* Continuous improvement initiatives (e.g., packaging optimization, load efficiency)
---
### **7. Issue Escalation and Resolution**
| Issue Type | Response Time | Escalation Contact |
| ---------------------------- | --------------- | ------------------------------ |
| ASN Transmission Failure | 4 hours | Supplier EDI Lead |
| Missed Delivery or Late Load | 24 hours | Supplier Logistics Coordinator |
| Product Damage or Shortage | 48 hours | Retailer DC Operations Manager |
| KPI Deviation >5% | 5 business days | Joint Supply Chain Council |
If unresolved, issues are escalated to the **Supply Chain Governance Committee** for mediation and action planning.
---
### **8. Compliance and Corrective Actions**
* Persistent KPI underperformance (two consecutive quarters below SLA thresholds) triggers a **Corrective Action Plan (CAP)**.
* CAPs must define root causes, timelines, and preventive measures, reviewed jointly by both parties.
* Failure to implement CAPs within 90 days may result in financial penalties or contract suspension.
---
### **9. Financial Adjustments**
#### **9.1 Penalties**
* $250 per late delivery outside tolerance window.
* Freight reimbursement for Supplier-caused expedited shipments.
* Cost recovery for product loss or damage due to Supplier handling errors.
#### **9.2 Incentives**
* 0.5% quarterly credit on total invoice value for achieving OTIF ≥ 98%.
* Recognition in Big Cloud Dealz’ **Preferred Partner Tier**, granting priority order scheduling and expanded volume allocations.
---
### **10. Review, Renewal, and Termination**
* This SLA shall be reviewed annually, with KPI targets adjusted based on network performance and capacity.
* Either party may terminate this agreement with **60 days’ written notice** for cause or material breach.
* Absent termination, the agreement **automatically renews** under the same terms each May.
---
### **11. Signatures**
**For Big Cloud Dealz, Inc.**
Name: ___________________________
Title: Vice President, Supply Chain Strategy
Signature: _______________________
Date: ___________________________
**For Georgia-Pacific LLC**
Name: ___________________________
Title: Director, Customer Supply Chain Operations
Signature: _______________________
Date: ___________________________
---
We have 5 of these contracts in this retail logistics demo and each one is slightly different to make it fun and somewhat realistic.
In this article we're going to use Agent Brick's Information Extraction agent type to extract the above general text contract form into the consistent json data structure above.
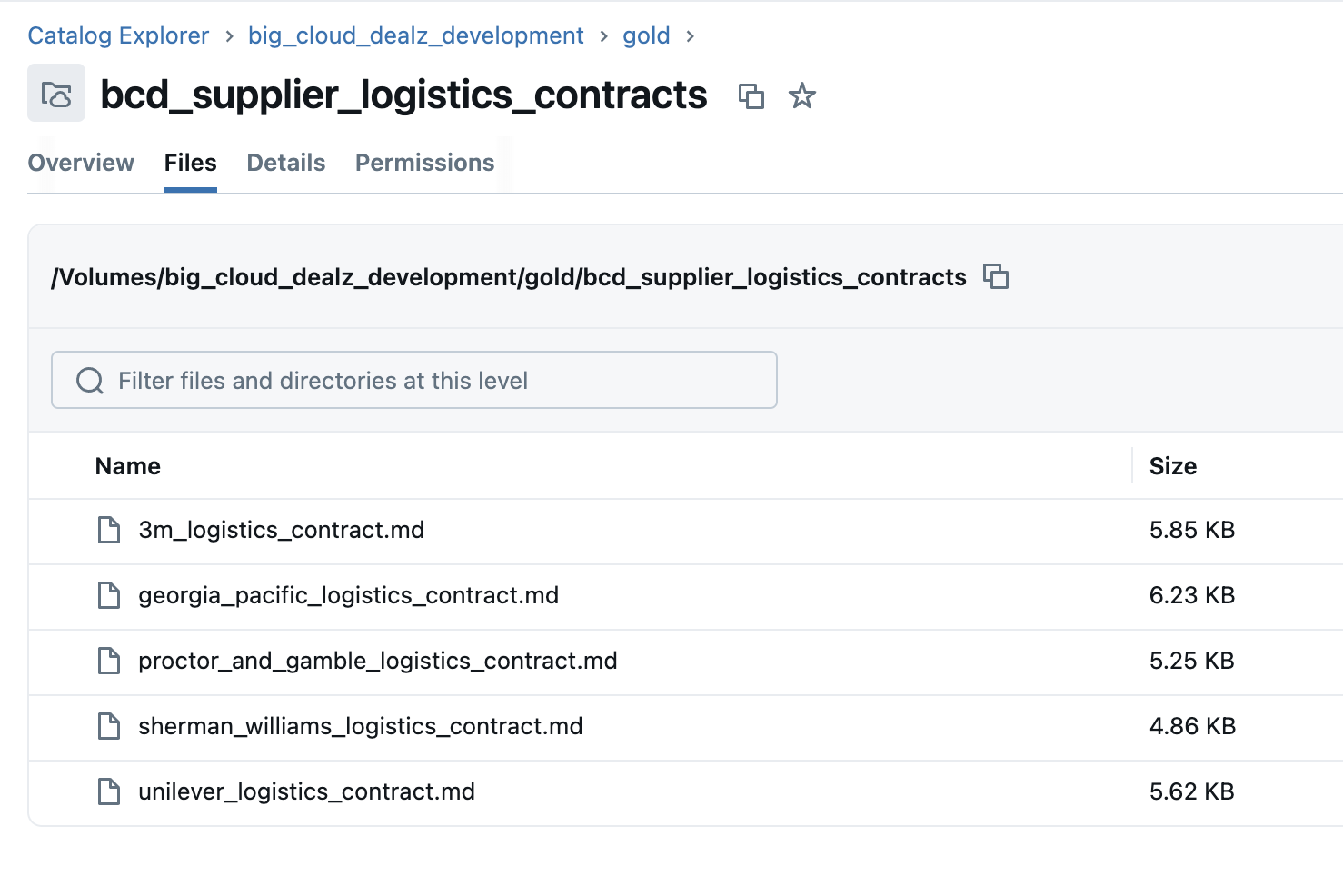
We've provided 5 contracts to test this agent with, and you need to upload these markdown documents to a volume named something meaninfuly, similar to the image below.
So now let's get going with filling out the core information of the agent configuration.
Information Extraction Agent Initial Setup
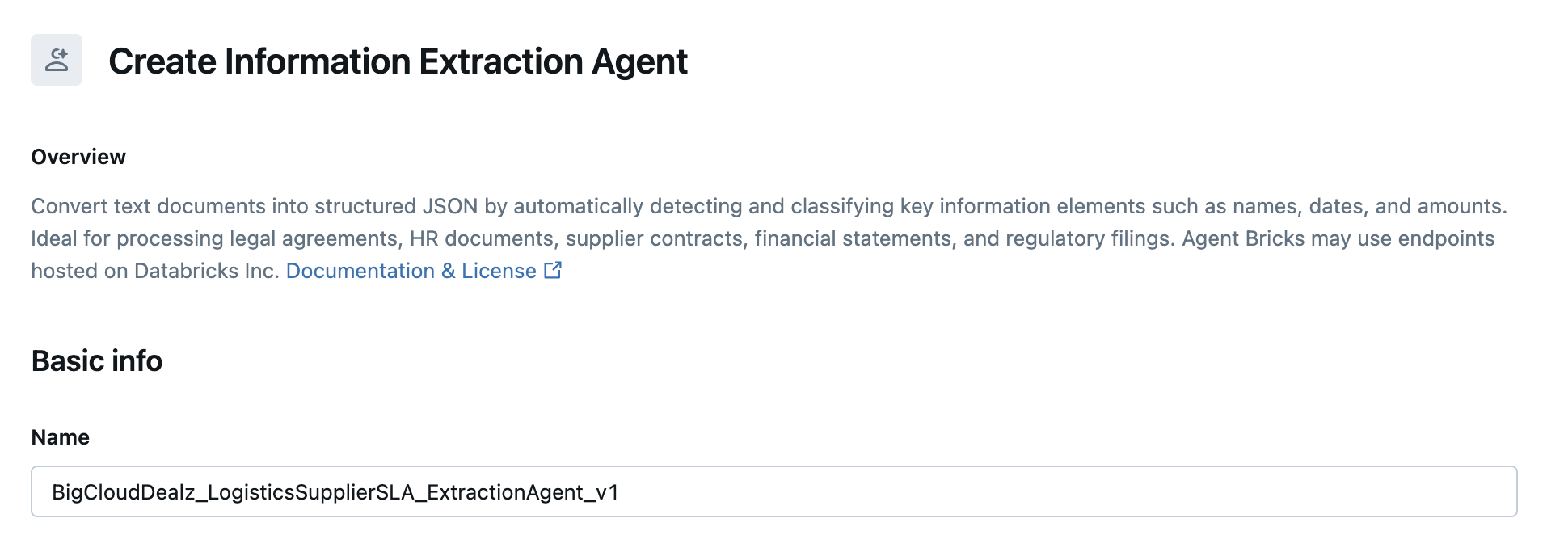
In the screenshot below you can see how to name the application (BigCloudDealz_LogisticsSupplierSLA_ExtractionAgent_v1).
For the "source data" here we are going to provide the example contracts that will show the agent examples (that we will later hand validate in an evaluation screen) on how to map the raw text into a structured json output. Click on "Browse text data" area as shown in the image below.
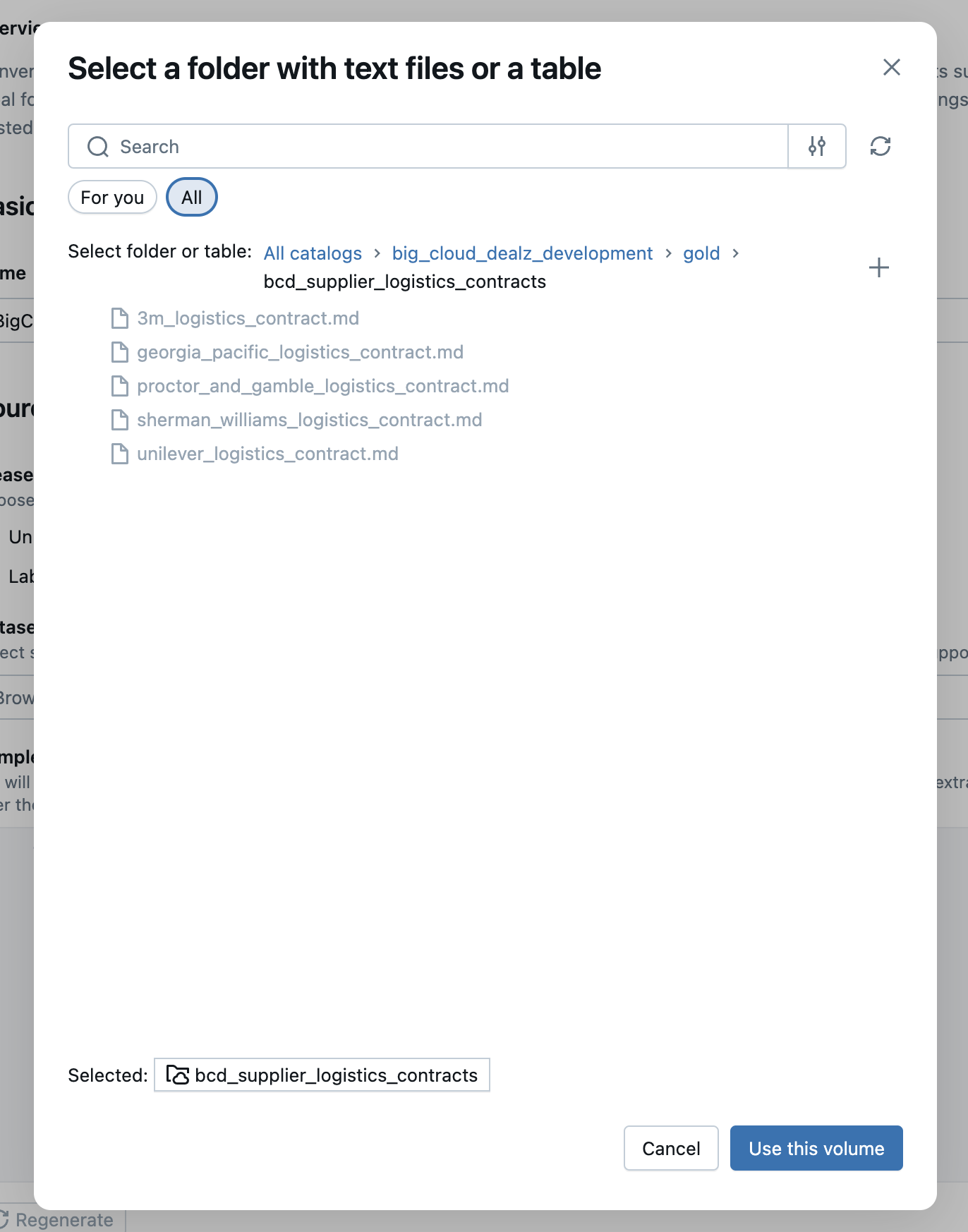
You should see a modal dialog that is similar to the one shown below in the image, find the volume or subdirectory where you uploaded the example contract markdown documents and select it.
Entering the JSON Data Structure
Now we need to show the agent a template of how we want the extracted data to look when it comes back to us for a given input contract text document. In the image below you can see the JSON structure from earlier in this article in the configuration area for the "Sample JSON Output". In your own agent, copy and paste the json above into your json text area as well (Don't worry if the values in the json don't exacly match the 5 documents, they are just examples of valid values for the LLM to learn from).
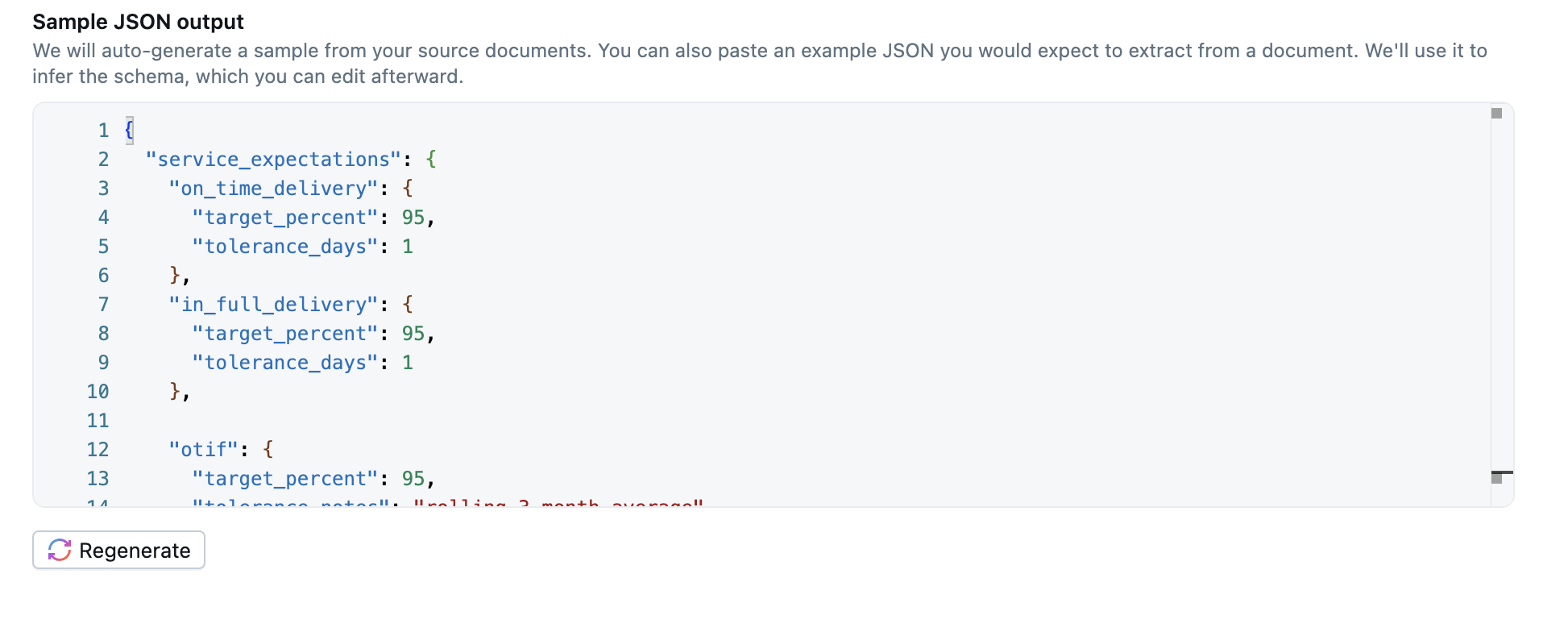
This is how we tell the agent "hey, when you read a given document, semantically find these fields and extract their values".
Click on Create Agent at the bottom right of the screen and we now have our agent.
Now that we a testable logistics contract information extraction agent, let's see how it does against our 5 contracts.
Testing the Information Extraction Configuration
Once the agent has been created, you should see a document mapping review page that let's you see how the agent extracted the structured information per document. You can see the list of the tested document mappings in the image below.
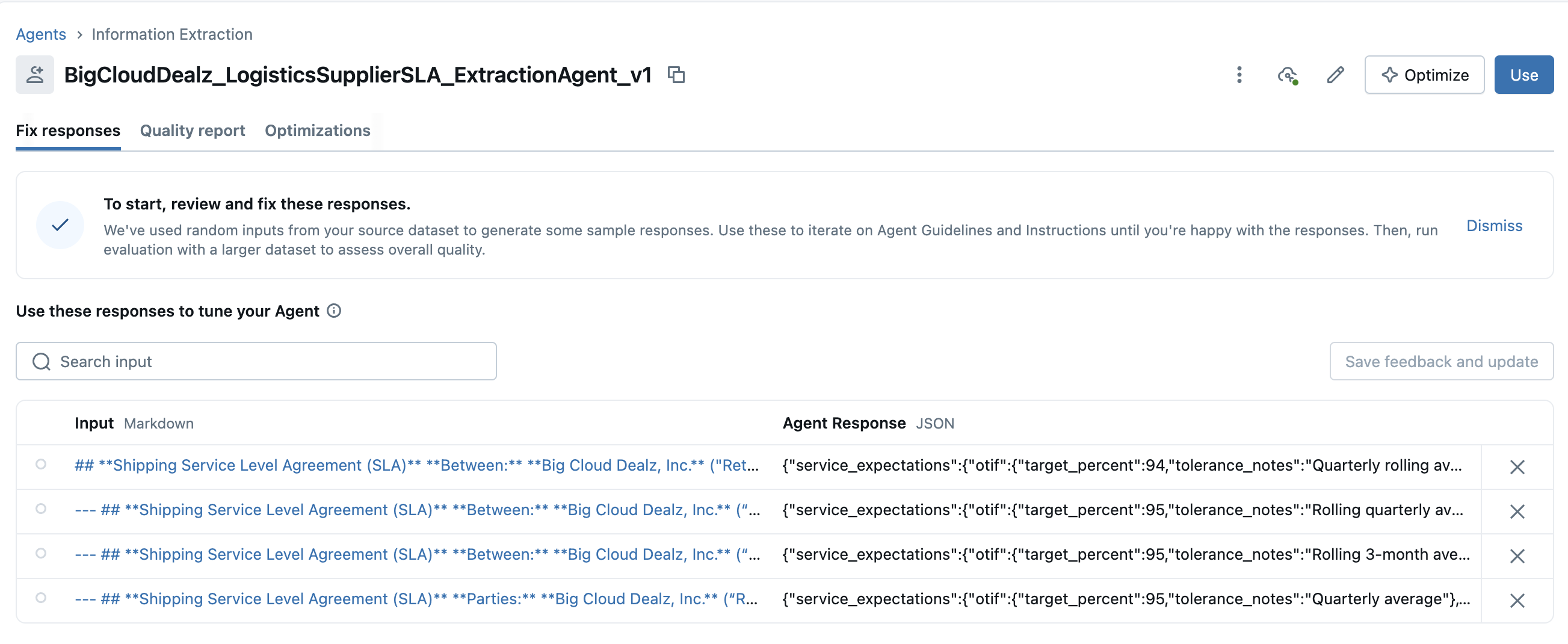
Clicking on one of the document example mappings in the user interface will give us a document mapping detail screen as shown in the image below.
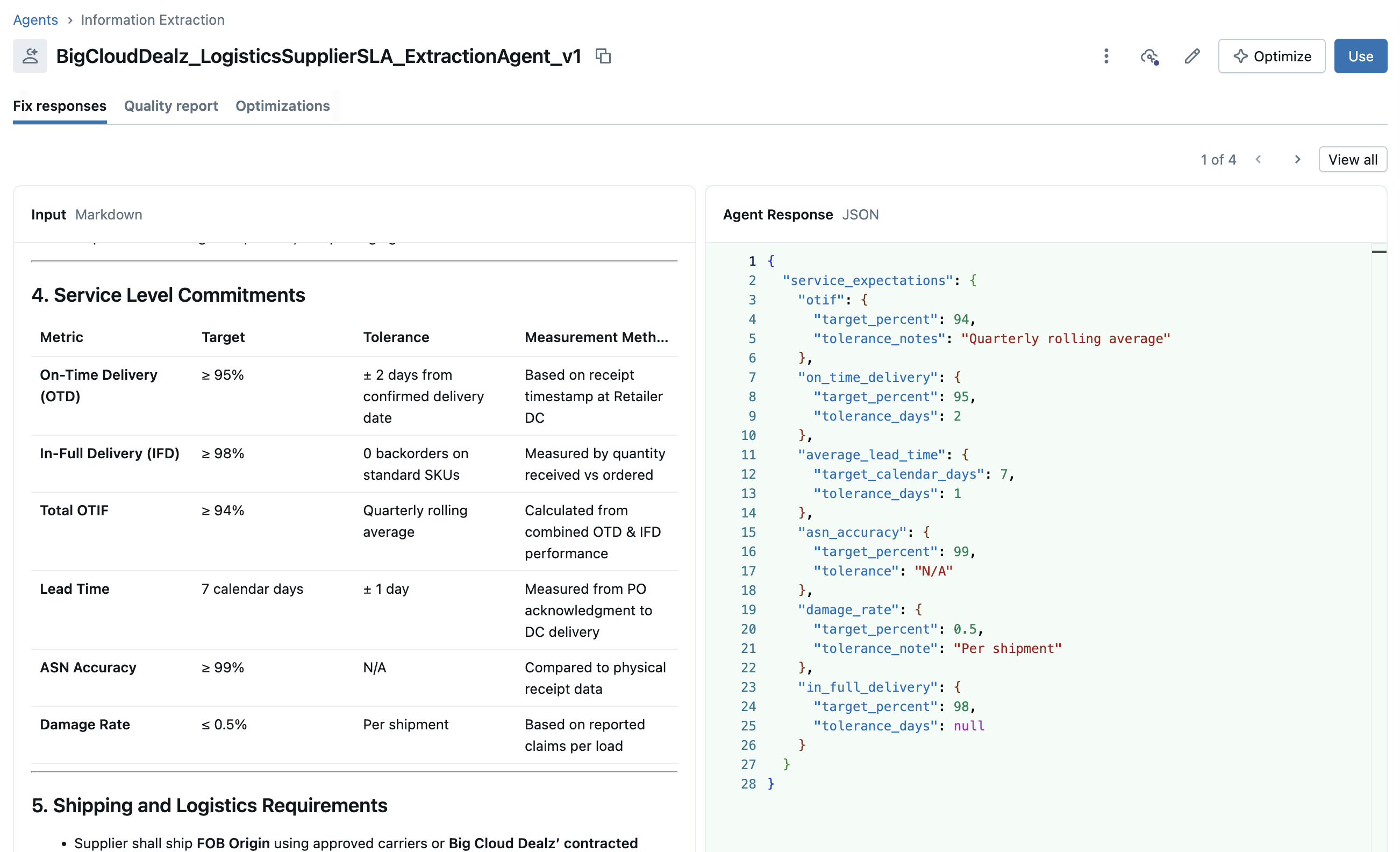
This allows us to hand validate that the agent is indeed extracting the correct information regardless of the structure of the text contract. We can give the system feedback per document and per field by updating incorrect extracting fields and having the system re-run the extraction.
We also have the option of editing the per-extracted-field intructions in the configuration panel on the right side, as seen in the image below.
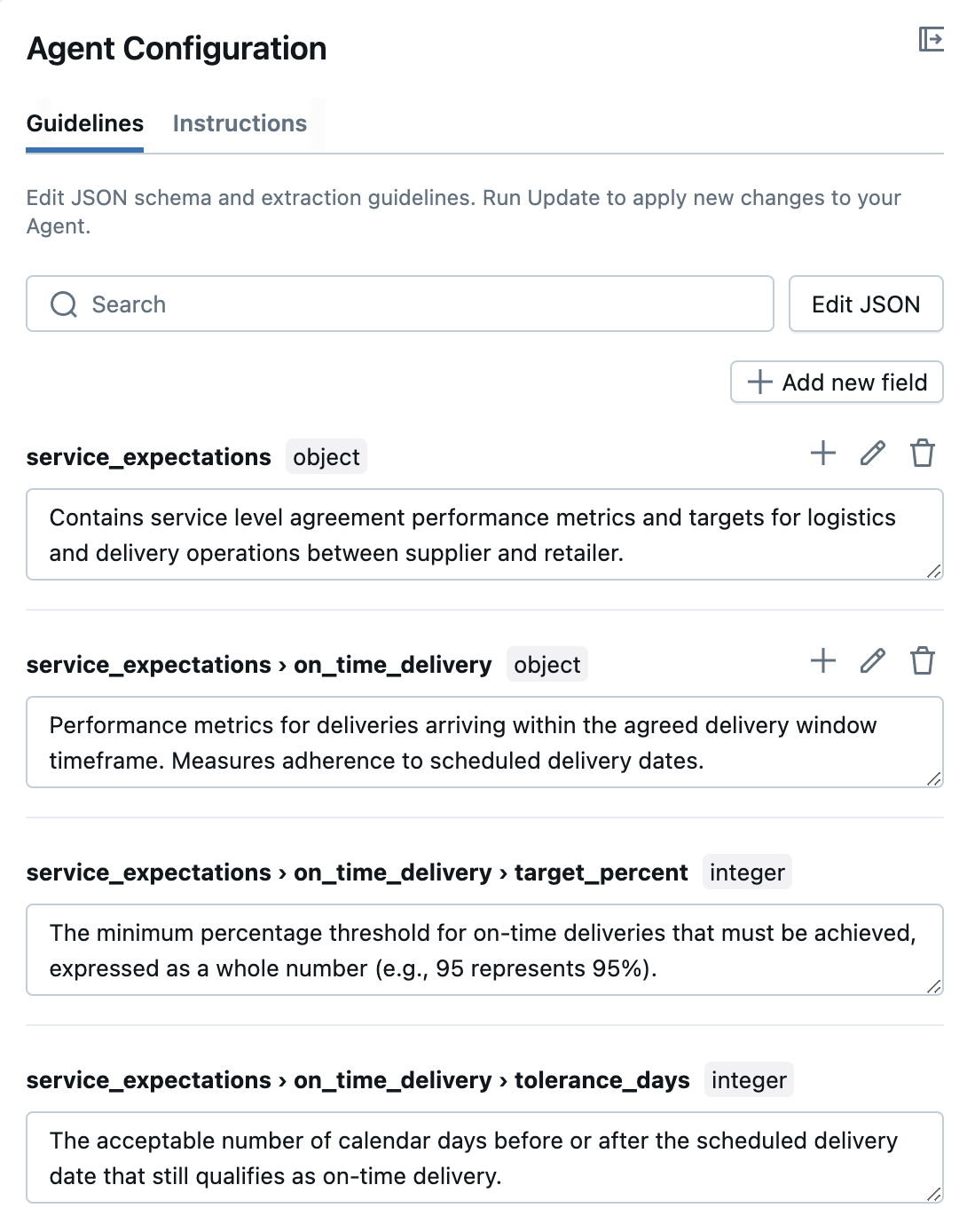
This gives us the ability to "hand train" the agent in a natural and relatable way. We can just say "hey, you got this one document wrong, but let's tweak things a little and then try again". This is more of a natural learning mindset towards "agent training" than what we did back in the traditional machine learning days.
Ok, once you have your agent working just the way you want it, let's put it in the water and try out different wants we can do information extraction in automation workflows on our Databricks lakehouse platform.
Testing Our New Deployed Contract Information Extraction Model Endpoint
To close this article out, we're going to work through 3 ways that this information extraction agent can be used on the Databricks lakehouse platform.
- Using the deployed model from the Playground UX
- Using the deployed model from the Python API
- Using the deployed model from SQL
Using the REST API Endpoint from the Playground UX
The absolute quickest and easist way to try out your new information extraction deployed model is to click on the Use button in the top right hand corner of the model page. This will give you the modal dialog as seen below.
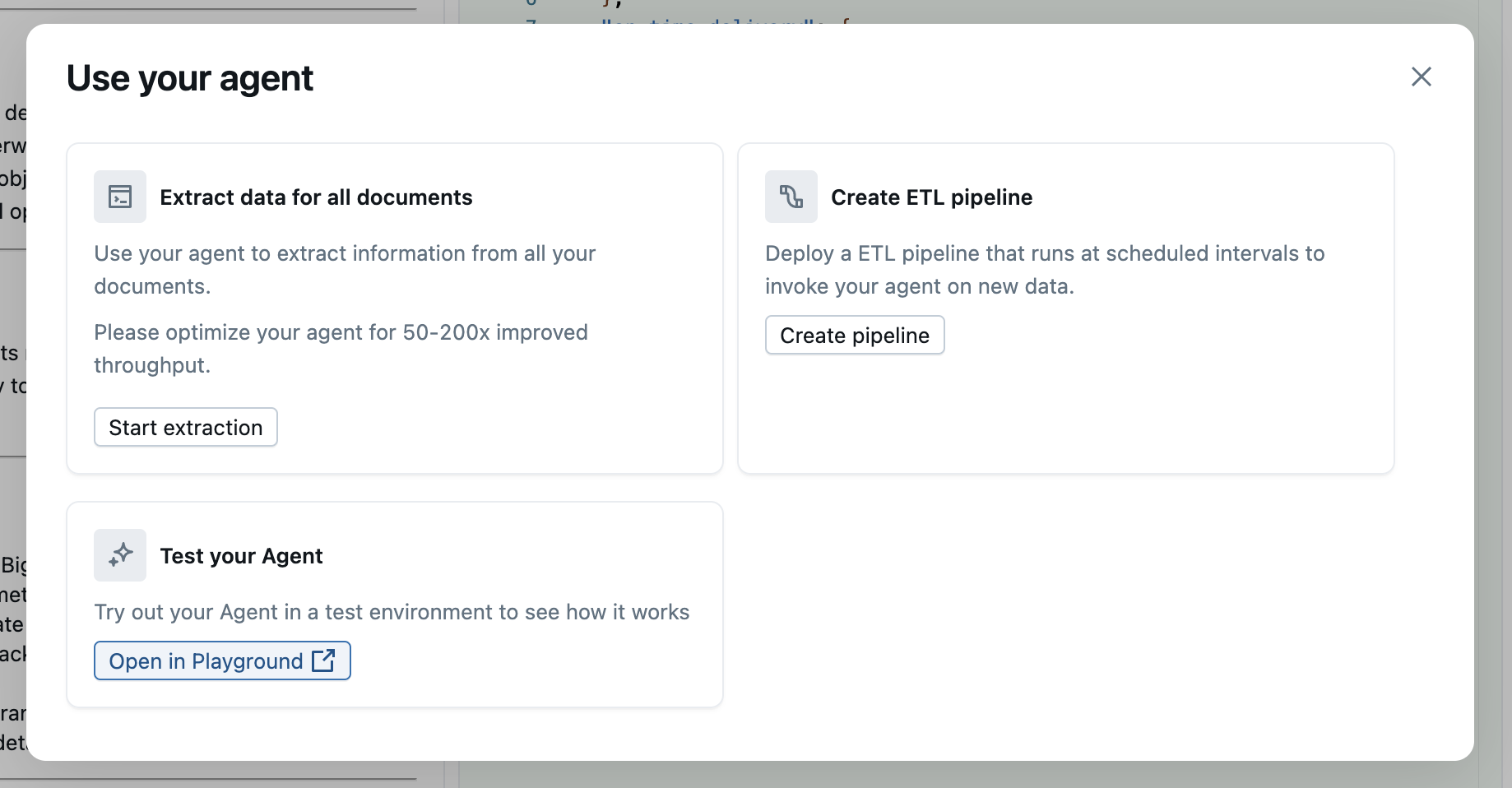
From there select "open in playground" under the "Test your agent" box. This will give you the model playground interface as shown in the image below.
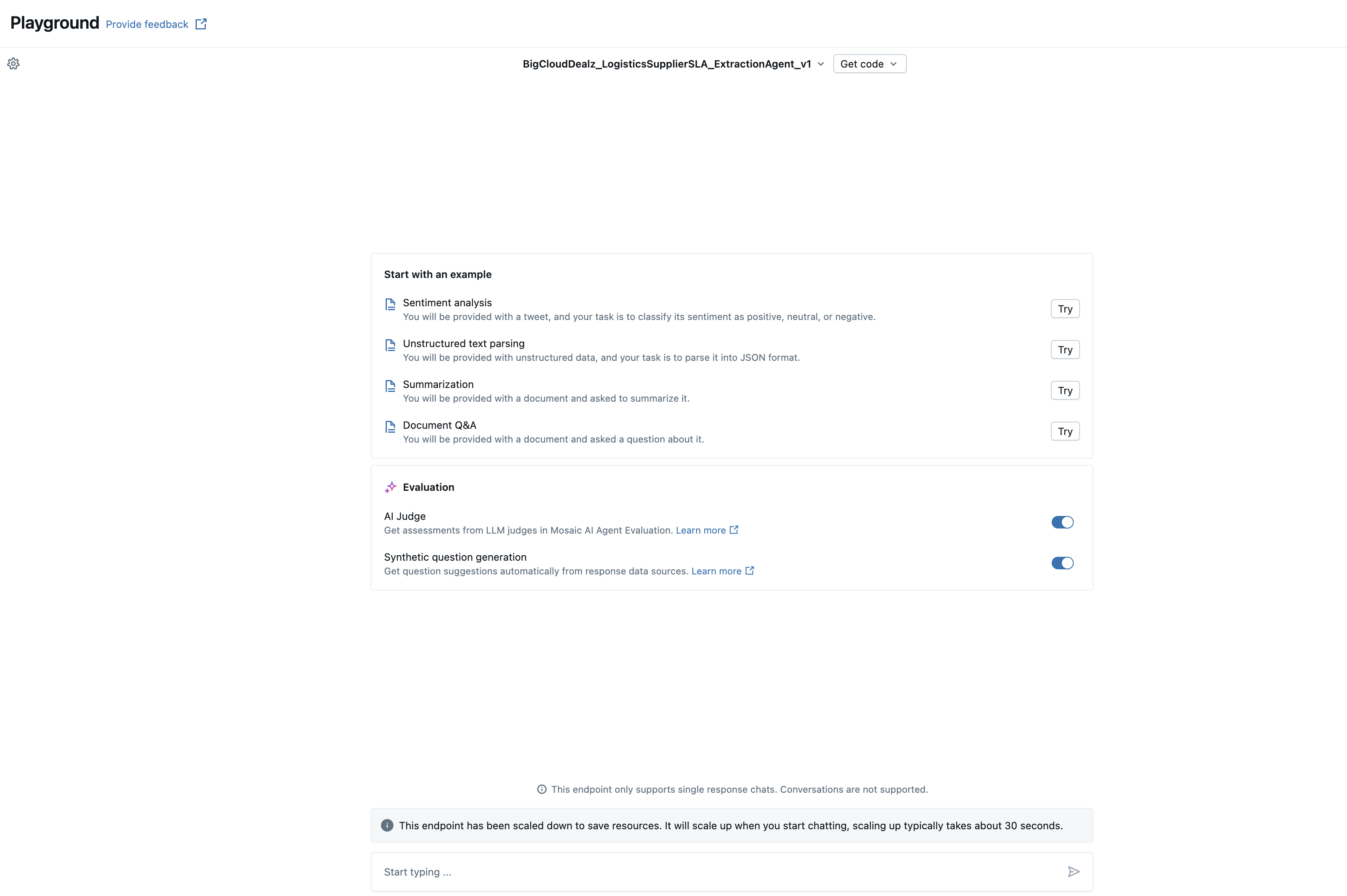
The super easy thing now is all that you have to do to test this model is to copy and paste the contents of one of the contracts into the text bar at the bottom and hit enter. The model will then analyze the document and return back the json generated to you in the chat playground interface for you to evaluate, as shown in the image below.

Naturally once you are confident the model is working correctly your next question may be "so how do I wire this into a python application?". For that, read on into the next section.
Using the REST API Endpoint from Python
To quickly get the code you'll need to call this deployed model from your own python application remotely, click on the Get code button at the top of the Model Playground screen and select Python API, as shown in the image below.
The generated code will be similar to the example code the example below.
from openai import OpenAI
import os
# How to get your Databricks token: https://docs.databricks.com/en/dev-tools/auth/pat.html
DATABRICKS_TOKEN = os.environ.get('DATABRICKS_TOKEN')
# Alternatively in a Databricks notebook you can use this:
# DATABRICKS_TOKEN = dbutils.notebook.entry_point.getDbutils().notebook().getContext().apiToken().get()
client = OpenAI(
api_key=DATABRICKS_TOKEN,
base_url="https://dbc-aaaaa111-b111.cloud.databricks.com/serving-endpoints"
)
response = client.chat.completions.create(
model="kie-1a1a1a1a-endpoint",
messages=[
{
"role": "user",
"content": "[ document content here ]"
}
]
)
print(response.choices[0].message.content)
Of course you'd need to put your document raw text in the content field above, replacing "[ document content here ]". Now let's move on to how we can scan a Delta table full of raw text documents and extract the information into json all from SQL.
Using the API Endpoint from SQL
If you go back to the "Use your agent" dialog above, there is another option called "extract data for all documents". If you click on that, you'll see the SQL Editor come up with a pre-generated SQL query similar to the one you see in the image below.
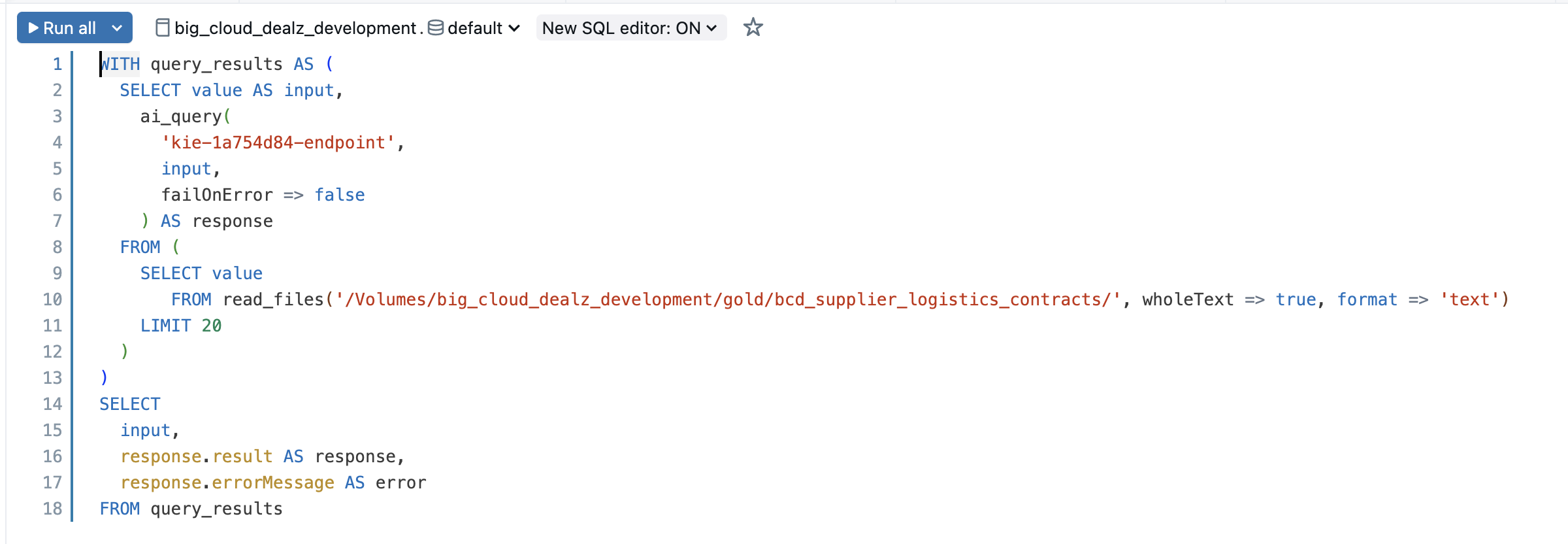
If you hit the run button, the SQL statement should execute and run "out of the box" on the 5 configuration contract documents in your Unity Catalog volume. The results should look similar to what you see in the image below.

At this point you should have a decent grasp on how to get going with structured information extraction for most any type of basic contract. There will be variations to tune for, and more tweaks to do in complex situations, but this article gives you the foundations to go for more down the road.
Text Documents Become Part of the Data Lakehouse
In this article we showed you how to build a foundational information extraction Agent Bricks agent that can pull structured json data from raw text markdown contracts.
This technique enhances the Big Cloud Dealz logistics team's ability to quickly integrate SLA information into their AI/BI dashboards, and also improving the ability of their Decision Intelligence systems to analyze KPIs against SLAs to better direct next actions with the management team.
This is another way Big Cloud Dealz is using Databricks and Generative AI workflow automation to become the next generation retailer of choice.
Next in Series
Connecting to Your Claims Data Model from Azure PowerBI
Quickly using your claims data models in a Power BI dashboard with the Cube connector.
Read next article in series