Platform Architecture for Ingesting Bordereaux Data
Running an insurance company is fundamentally about managing a budget and accurately forecasting costs.
Underwriting, claims, actuary, and finance all have to work in concert on the same view of common information to minimize the error in operational budgeting and forecasting.
When you miss on either of budgeting or forecasting the consequences are felt across the company. Your technology investment as a property insurance company should be focused around minimizing the error in budgeting and forecasting by giving each division a way to work off common information.
You provide common information to your knowledge workers through information architecture. This article will take you through the planning sesson for designing the information architecture for a mid-sized property insurance company that works with multiple TPAs for claims processing.
Property Insurance Knowledge Work
The data consumer in this scenario we are focused on is the claims team, and specifically the chief claims officer. This knowledge worker uses reports and dashboards built in a business intelligence tool (Power BI, Tableau, etc) to make business decisions about how to deal with potential future losses that might disrupt cash flow in the company.
Knowledge workers like the chief claims officer need data platforms that reduce friction and accelerate turning raw data into actionable insights, ensuring data consistency, reliability, and ease of use. The platform should enable flexibility in managing data structures, efficient query performance, and support interoperability across various analytics tools. Just giving the chief claims officer direct access to the raw data coming in from parter TPAs is not effective as your company scales. The chief claims officer operates on information, not data.
Data engineering transform pipelines operate on data.
Knowledge workers operate on information.
The job of the data platform is to transform data into information and your data storage strategy directly affects how efficient this data transformation is performed.
Further, you need to consider how your chief claims officer wants to work with her information. Examples of line of business knowledge work tools for a chief claims officer are:
- Business Intelligence tools (Power BI, Tableau)
- Report generation tools
- Spreadsheets (Excel, Google Sheets)
- Dashboards
- LLM Automation Workflows
Most of the time, the end-user claims knowledge worker will be operating off a materialized view (information) of the raw data. How this raw data is arranged (information architecture) and processed is a key architectural decision in any data platform.
In the diagram below we see the knowledge work architecture abstractions of the knowledge work layer, the information layer, and the infrastructure layer.
Knowledge Work Layer
- Business processes using information
- People using expertise with information
- Convert information into revenue
Information Layer
- Data model definitions
- Semantic layer
- APIS: SQL, REST, GraphQL
Infrastructure Layer
- Cloud infrastructure
- Databases, ETL pipelines, Servers
- Data Governance, Security
At Patterson Consulting we frame every data platform project and tool in this framework to keep outcomes aligned on impacting the line of business through the knowledge work layer.
Given that the line of busniess tools (Excel, PowerBI, etc) in the knowledge work layer operate on information, not data, we need to build a logical materialized view of the claims information needed (our claims data model) in the information layer. This materialized view of the information needed at the knowledge work layer will be in a low-latency cached system.
Planning Platform Architecture for a Property Insurance Claims Data Platform
The key things we need to do to develop our platform architecture for ingesting bordereaux data are:
- Provide a system to store and integrate the materialized view of the information we are providing to the knowledge work layer for claims workflows (e.g., Excel, Power BI, etc)
- Develop a transformation pipeline to combine and transform the raw claims data into usable and complete claims information to be stored in the information layer
- Select a storage architecture and information architecture for our data pipeline
You want to make architecture decisions that will work well with the needs of the whole platform, not just one department. The value of good architecture is make all the parts work together as a cohesive whole in way that reduces the friction on information transformation.
We're Only Designing for Claims at This Point
The challenge of platform architecture is that there are many line of business users in the knowledge work layer spread across multiple business divisions. A full knowledge work architecture review considers more constraints and goals than a single division. In this series we're walking through how we help property insurance companies develop claims knowledge workflows. We are purposely ignoring (for brevity and focus) other factors that come into play when we do a full knowledge work architecture review.
If you'd like to talk more about what a full property insurance data platform might look like, check out our knowledge work architecture review offering.
To build the claims information for our information layer we need to pull together the multiple external sources of claims data. To do this, we need to capture the incoming bordereaux data from the TPAs and produce a unified version of the total collection of bordereaux data. With that in mind, let's take a look at how TPAs operate.
Building a Claims Data Model in the Information Layer
We are supplying a materialized view to spreadsheet and business intelligence users. The queries to this materialized view need to be responsive and not costly to re-run. The information that needs to be modeled is a refined version of the raw claims bordereaux data that comes from TPA partners.
We need a few things to support these claims materialized views (e.g., "information obligations"):
- business formulas for the claims data models
- a system to manage and serve the materilized views, including integration apis that work with existing knowledge work tools (Excel, Tableau, etc)
- a data pipeline to construct the view from raw incoming bordereaux data
There are several options for managing and serving materialized views of data models. These include:
- DBT data models materialized in Snowflake
- Cube Semantic Layer
Later on in this article, when we determine our storage system, we will tie the storage system decision to which of the above caching layer options works best with it.
Designing a Data Pipeline for Bordereaux Data Integration
We now need to build a data pipeline to process the incoming bordereaux data for the construction of the claims data models. Given that most TPAs don't send more than a few hundred rows per day at most, we won't need a distributed framework for data transformation if we can avoid using it.
A property insurance TPA (Third-Party Administrator) is an external service provider that manages claims processing on behalf of the insurer. While the insurer retains final decision-making authority and financial responsibility, the TPA handles key operational tasks such as intake, investigation, and coordination with adjusters or contractors. This model allows insurers to scale efficiently, reduce internal workload, and improve responsiveness, particularly during high-volume or specialized claim events.
TPAs email excel spreadsheet files containing the rows of bordereaux data to the insurance carrier periodically (this is the industry norm).
Some TPAs use full "truncate and reload" data feeds rather than incremental updates, sending the entire claims dataset each time regardless of changes. While each claim remains a single row, these full refreshes can become increasingly bulky over time, especially as monthly claim volume accumulates. This has implications for storage efficiency and pipeline performance.
Our TPA bordereaux data integration strategy for this platform will be to use Apache Airflow to watch an email account for incoming Excel spreadsheet attachments (seen in the diagram below).
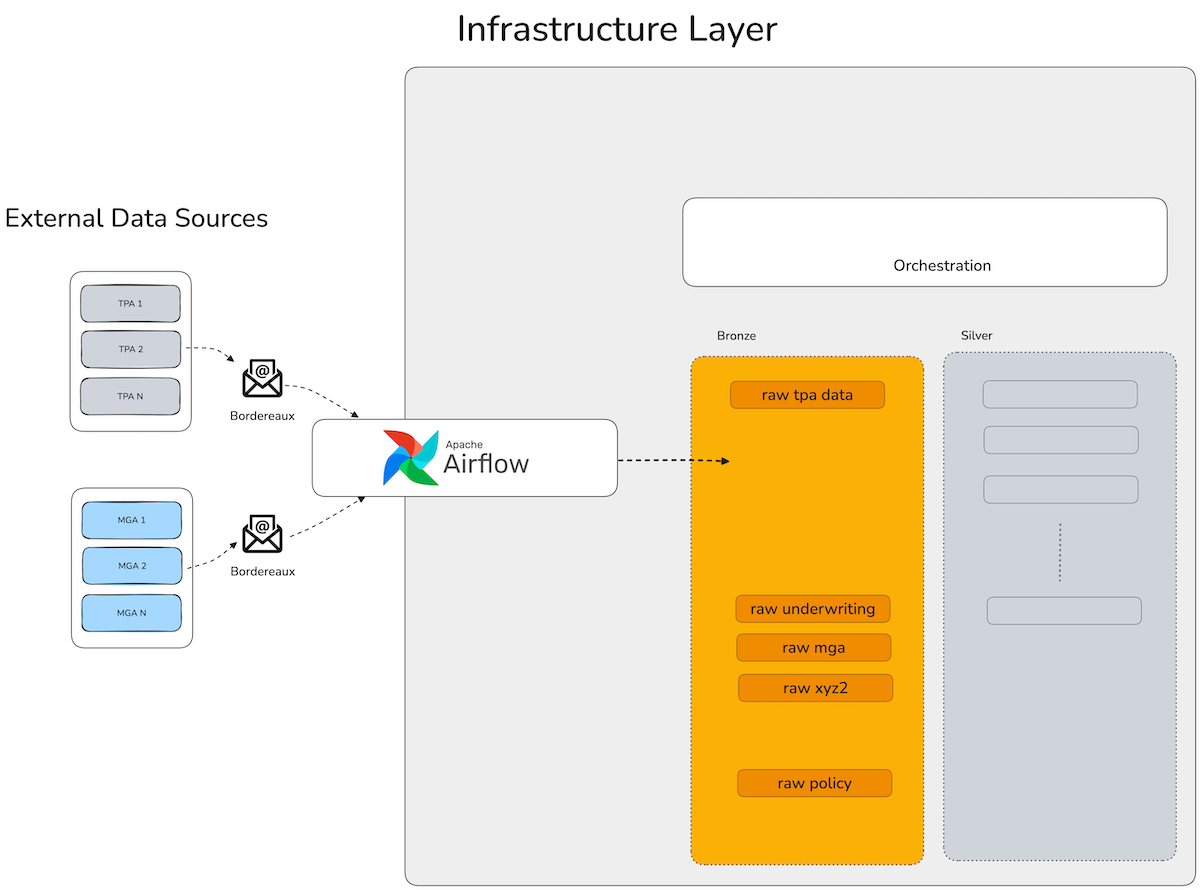
As it finds those emails, it will write the files into a directory (cloud blob storage, AWS S3, Azure Blob Storage, etc). From there they will be picked up into a processing pipeline post-processing before they are written into the staging tables in our data platform storage system.
For a full example on how to stand up Apache Airflow to capture email attachments, check out our blog post.
Testing TPA Data Integration with Synthetic Bordereaux Data
Testing new data platform architectures in property insurance presents challenges due to the sensitivity of claims and underwriting data. Regulatory and privacy constraints often prevent teams from using real data in development environments, making it difficult to quickly validate new ideas or system designs.
The Patterson Consulting team has developed a tool that generates realistic synthetic insurance bordereaux data to support safe and efficient development, testing, and demonstration of new platform capabilities. It models real-world claim behavior, maintains logical date sequences, and supports multiple output formats including JSON, CSV, and Excel. The tool also allows teams to simulate TPA data variations, introduce optional data inconsistencies for robustness testing, and customize outputs through a flexible schema configuration or command-line overrides. This enables faster innovation without compromising sensitive information.
For more details, check out our blog post on the bordereaux data generation tool.
Once we've landed the daily bordereaux files in a S3 blob storage directory, we'll use another Airflow pipeline to further convert all the files to a unified schema and then merge the files into a single daily batch for addition to our claims data model.
Once the daily batch of bordereaux data is added to our main claims dataset, the claims data models can be re-generated for the information layer and all the new information will show up in the knowledge work tools automatially. This gives us knowledge workflows in our line of business that continually have the most recent information allowing you to make the most informed budgeting and forecasting decisions possible.
Now we need to select a storage system for our claims data platform.
Here I'm mentioning "storage system" seperately from processing engine as we are in a period of "database disaggregation" and many platforms make those decisions seperately now.
To determine our storage system we need to estimate how large our dataset for the data platform will grow to be. To estimate the size of our data, we should take a look at the schema of the incoming raw bordereaux data.
The Bordereaux Schema
The bordereaux schema is not exact between every TPA (making integration tricky sometimes), but the general set of columns are:
{
"policy_number": "POL1038",
"months_insured": 113,
"has_claims": true,
"items_insured": 4,
"claim_reference": "CLM1071",
"insured_name": "Company 1038",
"policy_start_date": "2023-10-02",
"date_of_loss": "2024-01-16",
"date_reported": "2024-02-15",
"claim_status": "Open",
"loss_type": "Property Damage",
"paid_amount": 11463.65,
"reserve_amount": 11962.45,
"total_incurred": 23426.10,
"claim_propensity": 0.5
}
Estimating Size of the Data
Even at national scale, insurance data volumes remain manageable with modern architecture. The U.S. has 350 million people, 100 million households, 111 million structures, and 33 million businesses. Assuming generous coverage—two policies per person, one per structure, and one per business—results in fewer than one billion policy records. If 20% of those policies generate claims, the total volume stays under 200 million claim records. This back-of-the-envelope estimate shows that even in a scenario where one carrier insures the entire country, the data storage needs would be in the 200-300 million row range.
Given the above context, this means that a mid-market property insurance carrier would realistically only need to manage mid-10's of millions of rows in their data platform for claims data management.
With the above factors in mind, we will estimate our storage needs to forecast our storage system costs. The total storage needed for a PostgreSQL table with 15 columns and 20 million rows is around 10GB of disk space.
Selecting a Data Storage Strategy
Selecting a data storage strategy doesn't have to be ultra-complex for a data platform, but thinking through a few decisions can save you headache down the road. The major things you need to consider are:
- How important is reader/writer multi-tenancy support in this system? (Is this just me? or is a team using this system?)
- How much data do we need to manage with this system?
If you'd like to dig deeper on this topic, we have a blog post that goes into the details of selecting a storage strategy for a data platform.
In the case of our mid-market property insurance company, we need to manage 10-20 million rows of bordereaux data and run analytical queries over that data for claims operations. Because we will have a dedicated data pipeline to process daily data as it shows up via emails from TPAs, we'll need some way to make sure the readers of the data get a consistent view.
But Wait, My Other Dataset has a Ton of Data In It
You may say to yourself, "Josh we have other datasets beyond claims that need to be in a larger parallel cloud data warehouse".
Hey I get it, sometimes we have that one dataset in our business that blows up all the assumptions that we made for one side of our business. Another factor that is relevant is that we are in a period of "database disaggregation" and using a tightly coupled traditional RDBMS just may not be your jam.
To that end, we're writing parallel versions of this series where we are going to use different storage technologies (AWS S3-Tables, Databricks Delta Tables, etc) to show off the platform using different design choices. This opens up our query tool options as well, while still integrating well with our materialized view platform.
I also want to call out how there is not a single storage platform for any give data platform; The holy trinity of data platform storage architecture is:
- Blob storage: for landing raw files (typically the bronze layer in medallion data pattern)
- Data Tables: for processing incoming data, giving us scale and multi-tenancy (typically the silver nad gold layers in the medallion data pattern)
- Data Models: for providing consistent and complete information to the knowledge work layer (typically the gold layer in the medallion data pattern)
There's no perfect answer for what you'll need to select for storage, so I am going to walk you through several path choices and let you compare the experience and value yourself. This is the point in this blog series where I split the narrative into multiple sub-paths based on your storage architecture:
- Path 1: Postgres and local files
- Path 2: AWS S3 storage for blob storage, Databricks Data Tables, and Cube Semantic Layer for Data Models
- Path 3: AWS S3 Storage for blob storage, AWS S3-Tables for Data Tables, and Cube Semantic Layer for Data Models
What we are building towards in a full medallion data architecture pattern for capturing property insurance data and processing it into useable information. In the diagram below you can see the 3 layers of the knowledge work architecture framework map to the physical implementation of a data platform supporting the information obligations of the organization.
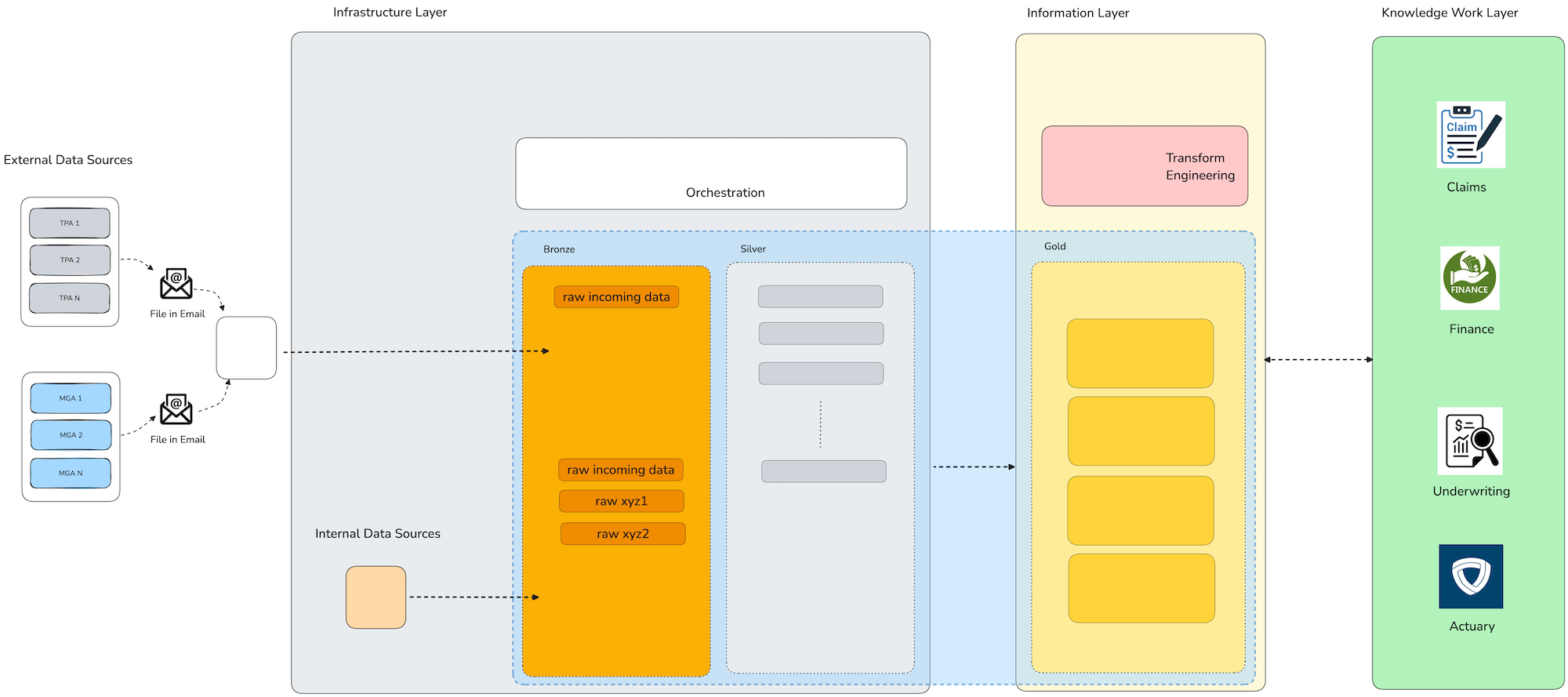
This generalized platform architecture represents the Patterson Consulting claims information architecture reference design. It not only represents the medallion data architecture design pattern, but also full aligns with the Patterson Consulting knowledge work architecture design pattern. The knowledge work layer on the far right side represents the 4 core divisions of a property insurance company (underwriting, finance, claims, actuary) and how they should connect to the platform through the information layer in order to maximize efficiency.
Now let's move on to the next stage in designing our architecture where we implement the data integration for bordereaux data emails with Apache Airflow.

Need Platform Architecture Help?
Patterson Consulting offers business workflow analysis, data strategy, and platform architecture review services. Check out our Knowledge Work Architecture Review offering.
Let's TalkNext in Series
Capturing Email Attachments with Apache Airflow
Automate email attachment capture with Apache Airflow.
Read next article in series