Selecting a Data Storage Strategy for Your Data Platform
The choice of data storage architecture directly impacts your organization's ability to efficiently query, manage, and scale large datasets on your data platform. A well-designed storage architecture enables critical capabilities such as schema flexibility, historical data analysis, and transactional reliability, essential for accurate analytics and operational agility.
Conversely, poor architecture choices increase complexity, reduce interoperability between tools, and raise operational costs, ultimately hindering strategic decision-making and long-term growth.
The core job of a data platform is to turn raw data into useful information—fast, reliably, and at scale. Knowledge workers rely on tools like dashboards, spreadsheets, and LLM-driven workflows that sit on top of low-latency, materialized views of this data. The structure and performance of the storage layer determine how easily this transformation happens. To support efficient pipelines and enable insight generation, the storage architecture must align with both the operational needs of data engineers and the analytical needs of end-users. This isn’t just about storage—it’s about speed, clarity, and making data usable.
Keys to Consider for Data Storage
You want a data storage strategy that seamlessly supports knowledge workflows, handling diverse data types and sources with minimal operational friction. Effective architectures should enable dynamic scalability without modifying existing workflows, ensure concurrency in multi-tenant environments, and allow multiple writers to interact safely with datasets. Compatibility with both SQL and Python pipelines is essential, as is eliminating unnecessary data movement, to ensure the infrastructure efficiently converts raw inputs into actionable insights.
A major theme in your decision criteria should be "let's keep this as simple as we can". In past lives, I've worked on complex distributed systems, and they are require a lot of care and feeding. If you can get away with "just a bunch of files in the directory for my own analytical queries" --- then you should do just that.
Selecting a Data Storage Strategy
I'm going to lay out the 3 major ways storage strategies come together for data platforms, describe each one, and then give you a generalized decision tree on how to map your situation to a specific strategy. The 3 major storage architectures are:
- DuckDB and CSV/Parquet Files ("Just a Bunch of Files")
- Traditional RDBMS
- Cloud Data Warehouse
Now let's dig into some notes about each one and then I'll put them together in simple decision tree on how to figure out where you should end up.
"Just a Bunch of Files"
If you are a single entity that has some data and needs to do some analysis locally (or even if the files are in the cloud in blob storage (s3, etc)) --- then this is the option for you. You just need DuckDB and you'll be able to analyze a ton of data quickly.
The thing that creates complexity in data platforms is multi-tenancy.
With "Just a bunch of files" you won't need to worry about operating databases or managing schemas or any other operational overhead because there just aren't any other users to worry about, so multi-tenancy is not a concern here. That makes things a lot simpler, and DuckDB makes the analytical queries fast.
Traditional RDBMS
Once you start needing to coordinate with other folks writing to the data platform "just a bunch of files" starts to break down as a strategy. That's where the traditional RDBMS makes more sense as the option for your data platform storage.
Traditional relational database systems offer a proven, structured foundation for managing high-value, transactional knowledge work. Their mature architecture ensures strong consistency, optimized indexing, and reliable query performance—all critical for enabling accurate, repeatable decisions in environments where data integrity and operational precision are essential. While they may face scalability limitations in high-volume, unstructured workloads, their stability and clarity of schema make them an effective core for platforms where structured data drives coordination, compliance, and business insight.
Cloud Data Warehouse
Cloud data warehouses provide the scalable backbone needed for modern knowledge work, where information must move fast and stay accurate. They support high-volume, concurrent writes and reads, allowing teams and systems to operate in parallel without bottlenecks. Their architecture handles everything from small lookups to massive historical datasets with efficiency, making it easier to maintain performance as demands grow. In fast-moving environments where data must be fresh, accessible, and reliable, cloud-native platforms offer the flexibility and throughput that traditional systems struggle to match.
The thing is, with cloud data warehouses the amount of operational overhead is a tier above just running a RDBMS. You are now running a distributed system with many components in the cloud to integrate, manage, and support. This produces operational overhead and costs that are not always obvious on the front end. You should only end up in this option when the need is evident and you understand your cost model well.
A Simple Decision Tree for Choosing Your Data Platform Storage Strategy
In the decision tree shown below I lay out a quick way to make a decision about where to start with your data platform storage strategy.
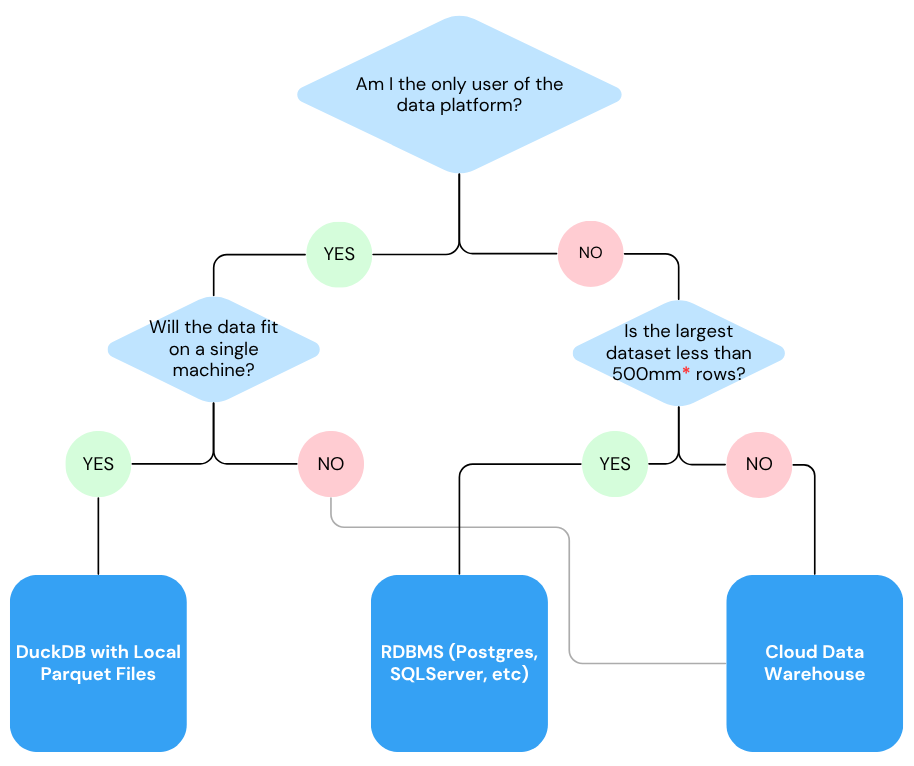
I think the first thing to call out in that decision tree is the "500 million row table" decision node;
This is just a rough estimate of the outside edge of where folks have to move to a cloud data warehouse.
Many times joins and transforms start slowing down and not responding to tuning far before you'll hit 500 million rows, causing a transition to a cloud data warehouse. It's not an exactly threshold, but the intuition roughly follows as:
- Up to tens of millions of rows: A well-optimized RDBMS (e.g., PostgreSQL, MySQL, SQL Server) handles comfortably.
- 50 million to 500 million rows: Performance begins to degrade; vertical scaling or extensive tuning required.
- 500 million to billions of rows: Typical tipping point where parallel cloud data warehouses (e.g., Snowflake, Databricks, Redshift, BigQuery) become advisable.
The things to look for when you're trying to make a decision on whether or not to move to a cloud data warehouse from a RDBMS are:
- Consistently slow query performance despite indexing and optimization.
- Frequent bottlenecks disrupting analytics workflows or reporting.
- Increased operational overhead, maintenance costs, or downtime.
The "back of the envelope" way to measure if your RDBMS data storage strategy is not the right choice for your platform architecture at this point is to consider:
If queries regularly exceed a few seconds to minutes and tuning offers limited improvement, consider migrating to a cloud data warehouse.
The "back of the envelope" way to measure if your RDBMS data storage strategy is not the right choice for your platform architecture at this point is to consider:

Need Platform Architecture Help?
Patterson Consulting offers business workflow analysis, data strategy, and platform architecture review services. Check out our Knowledge Work Architecture Review offering.
Let's Talk